Graylog with AWS Elasticsearch

Graylog has been through some changes last time I talked about them, hitting version 3.0 in February is awesome and one of things that make Graylog run well is Elasticsearch backend. Although Elasticsearch is not too hard to setup it usually runs better on bare metal, so there is cost of that as well as maintenance of the cluster is important, updates and upgrades. Depending your team experience you may not have time to learn it or run it the way it should be. That last thing you want is your logging setup to go down because of poor maintenance. So in this post we will walk though setting up a Graylog Server and using AWS Elasticsearch service for our backend. Without having a quick Elasticsearch cluster Graylog experience suffers, so let's get started.
The first thing and easiest thing is to spin up an Elasticsearch cluster within AWS. Depending on your use case you may only want a development deployment (single-node) or you can do a 3 or 2 node cluster within different availability zones within AWS, so its up to you and your wallet ;) of how big or small you want this Elasticsearch resource.
Additional security protections are recommended if this going to be used for production, like one example is don't open Elasticsearch to the internet without ACLs in place!
If you want more information about Elasticsearch service that AWS provides go ahead and read AWS Developer Guide - Amazon Elasticsearch Service.
Once your cluster is up and running, keep note of the Endpoint URL you will need that for Graylog. In this example I'm using Centos 7 for the Graylog Server and depending on the operating system you are using for the Graylog server follow the instructions on Graylog's Read the Docs.
No need for me to repeat installation steps, in this example I'm using Centos 7 and followed the documentation. Since we have an Elasticsearch cluster provided by AWS you don't need to anything related to Elasticsearch when installing Graylog, so skip it. Once you have Graylog installed go ahead and start it up to make sure you get the webpage and can login. This just verifies you have a working Graylog server ready to go. You might see some errors related to indexing but that is expected, we have not told Graylog about our AWS Elasticsearch resource.
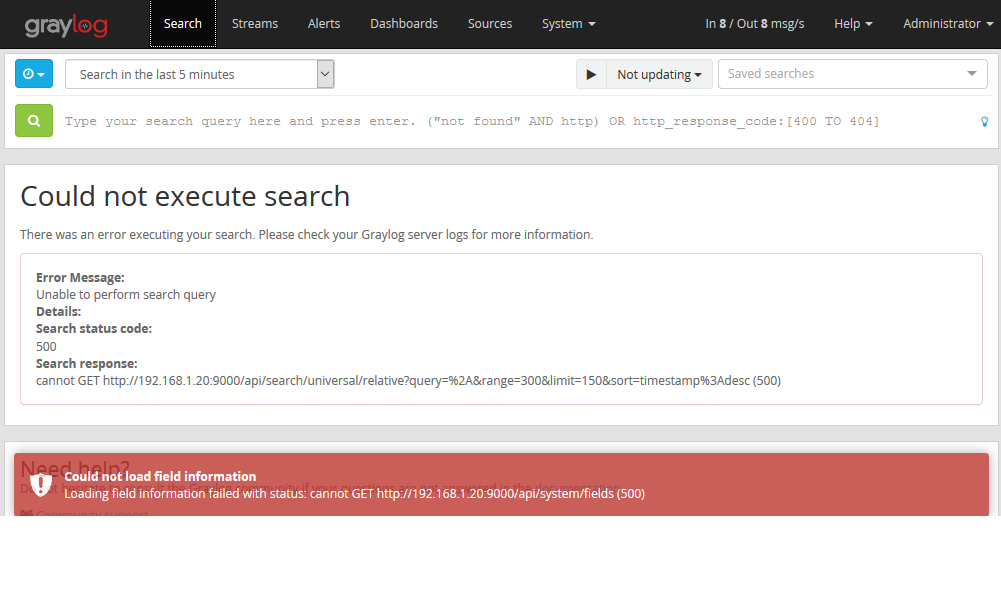
Login into your Graylog server and with your favorite text editor open the Graylog server configuration file /etc/graylog/server/server.conf We are looking to modify the Elasticsearch hosts by default its local host to the Endpoint URL that is in your AWS Elasticsearch resource.
1# List of Elasticsearch hosts Graylog should connect to.
2# Need to be specified as a comma-separated list of valid URIs for the http ports of your elasticsearch nodes.
3# If one or more of your elasticsearch hosts require authentication, include the credentials in each node URI that
4# requires authentication.
5#
6# Default: http://127.0.0.1:9200
7elasticsearch\_hosts = https://search-24726754557.us-west-2.es.amazonaws.com/
Restart the Graylog server service
1systemctl restart graylog-server
You now have Graylog server backed by an AWS Elasticsearch Cluster, log away :)
AWS makes deploying Graylog even easier if you don't want to have your own Elasticsearch cluster. Although you can't stop the AWS ES Cluster you can snapshot the data to an S3 bucket and import it back into a new ES cluster and connect Graylog back to it. This makes it so you don't have this running 24x7, maybe useful for temporary debugging logs or run it 24x7. Well that's all I got for a Friday, and its the first day of summer "officially" so time enjoy it! I do hope this information is helpful but also enjoy your summer! 8-)